The Board AI Governance Readiness Index is Governance AI's planned methodology for comparing how UK boards evidence AI oversight: named accountability, live risk evidence, data-protection discipline, regulator mapping and decision controls. It will publish findings only after enough anonymised tool data and human review.
This is not the first benchmark report. It does not claim sector averages, sample counts, readiness scores or anonymised findings from our own tools. The purpose of this page is to set out the design: what the index will measure, what evidence will count, what will be suppressed for anonymity, and what a board should do before treating any number as assurance.
The index is designed to sit beside our Board AI Scorecard, the AI governance diagnostic, and the board accountability articles on governing capability you did not build and keeping an AI risk register as living evidence. The first public report will wait until there is enough anonymised scorecard and tool data to say something useful without identifying organisations or dressing thin evidence as research.
Key takeaways
- The index is a methodology first, not a findings page; no Governance AI benchmark claims should be quoted until the first reviewed report is published.
- Readiness will be measured by evidence a board can inspect: owners, registers, DPIAs, control logs, assurance routes and documented decisions.
- Adoption and governance are different measures. A board can use many AI tools and still be unready if it cannot prove who is accountable and what controls operate.
- No sector pattern should appear unless the data cell is large enough, anonymised enough and reviewed by a human before publication.
- The right next step today is to complete the scorecard or diagnostic so the board can improve its own evidence before it is compared with anyone else.
Who this applies to and what the board decides
The index is intended for UK boards that already have AI in use, whether approved, bought through a supplier, embedded in existing software or used informally by staff. It is most relevant to regulated organisations, charities, housing associations, education bodies, professional services firms and financial services firms, because those boards already have duties around risk, assurance, fairness, confidentiality, data protection and internal control.
The first board decision is scope. The index should not ask, "Are we using AI?" That question is too shallow. The useful board question is, "Can we evidence the controls around the AI we use?" For that reason, the index will separate adoption from readiness. It will treat a wide deployment with poor evidence as less mature than a narrow deployment with named accountability, clear boundaries and records that survive scrutiny.
A board should agree four things before relying on any readiness benchmark:
- What counts as evidence. A policy, register or committee paper is useful only when it points to a named owner, a live system, a date and a control.
- What the benchmark is allowed to compare. A sector comparison is only meaningful when the sample is large enough and when the organisations in it cannot be inferred.
- Who reviews the interpretation. A score produced by a tool is not a board conclusion. A person must check whether the evidence supports the claim.
- What action follows. The benchmark should route into board decisions: which AI uses are paused, which controls need investment, which suppliers need review, and which issues must come back to the audit or risk committee.
That decision frame is the same one we use in our guide to questions every UK board should ask about AI: the output that matters is not reassurance in the meeting, but a dated artefact the board can revisit.
How the Board AI Governance Readiness Index will work
The index will draw from three sources when the data exists: scorecard completions, structured diagnostic or tool outputs, and human review notes where a Governance AI adviser has checked the evidence. Self-assessment can start the record, but it should not finish it. The first report design therefore uses evidence tiers rather than treating every answer as equally strong.
Tier one is a board assertion, such as "we have an AI policy". Tier two is documentary evidence, such as a dated policy, an approved risk register entry or a supplier due-diligence pack. Tier three is operating evidence, such as an exception log, an append-only decision record, a completed DPIA, a control test or a board paper showing how a decision was made. The index will favour tier three because it tells a board what is happening, not just what the organisation intended.
The first report should also disclose its method in plain terms. The Bank of England and FCA 2024 survey on AI in UK financial services is a useful reporting precedent, not a board-readiness benchmark for all sectors: it states that results were anonymised and aggregated, grouped respondents by sector, and disclosed 118 responses. Our first report will need the same discipline around sample definition, aggregation and limitations before any pattern is published.
Until that threshold is met, the responsible statement is simple: the index methodology is ready to use for individual board diagnostics, but Governance AI does not yet have publishable anonymised benchmark findings.
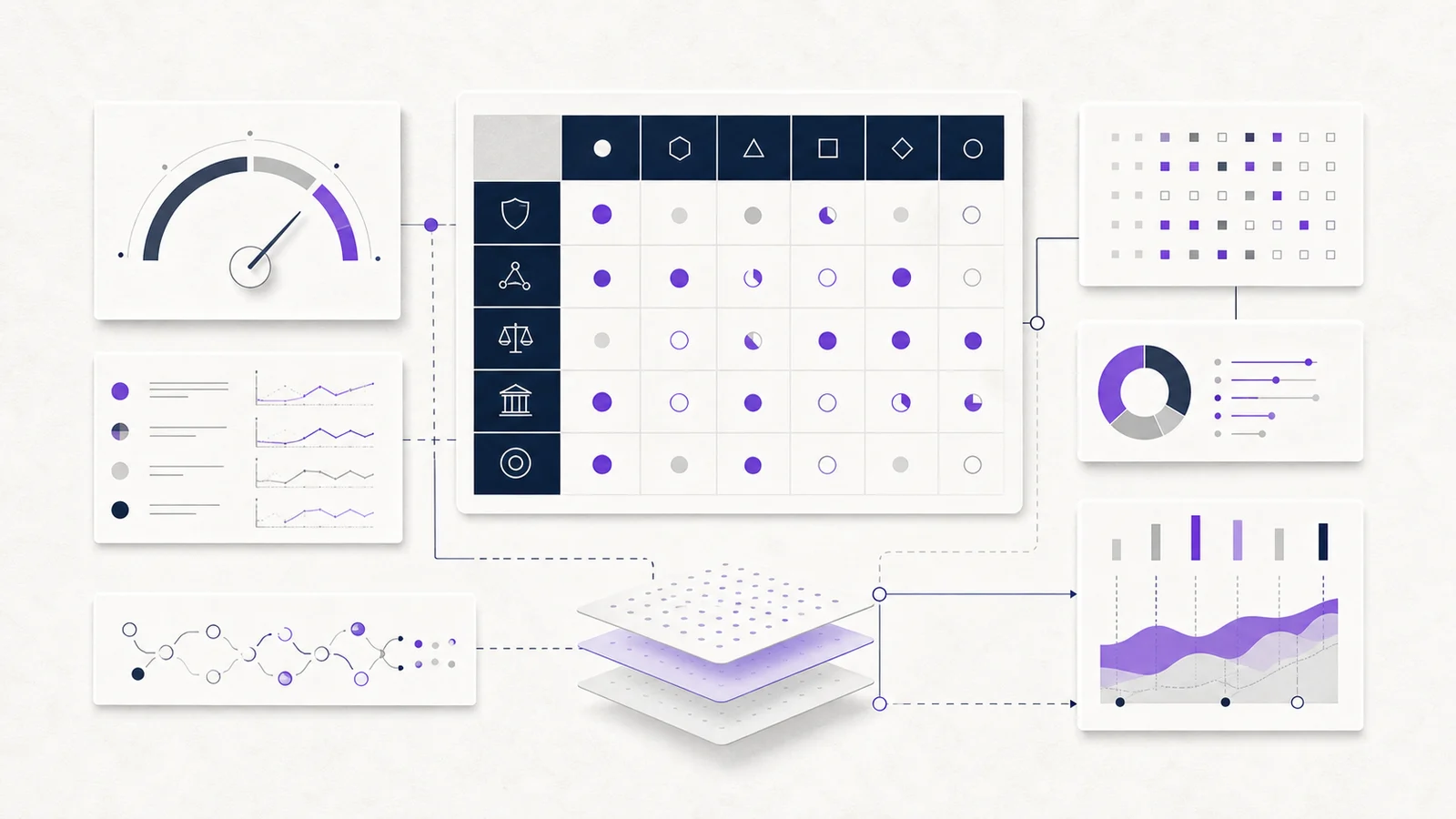
Methodology and evidence table
The index will score readiness by dimension, not by a single unexplained grade. Each dimension should be traceable to a board question, an evidence standard and a review rule.
| Dimension | Board question | Evidence that counts | Review rule |
|---|---|---|---|
| Accountability | Who owns AI use, exceptions and escalation? | Board or executive owner, committee terms, decision rights, escalation route | Job title alone is not enough; the owner must be able to act |
| Inventory and risk map | Which AI systems exist, where are they used and what could they affect? | AI use-case register, system purpose, data touched, affected groups, supplier status | Shadow or embedded AI must be captured, not only approved projects |
| Control evidence | What stops the AI doing the wrong thing, and can the board see it working? | Risk register entries, human review logs, output checks, testing records, incident and exception logs | Operating evidence is weighted above policy evidence |
| Data protection and fairness | Where personal data or people-impacting decisions are involved, what assessment exists? | DPIA, lawful-basis record, fairness review, automated-decision safeguards, privacy notice wording | Sensitive uses require a named review date and legal owner |
| Third-party dependency | What is supplied, what changes without notice and how would the board exit? | Vendor due diligence, data-processing terms, model-change record, service dependency map, exit plan | Supplier assurance cannot replace the board's own control evidence |
| Reporting and assurance | What does the board see, how often, and what is independently checked? | Board pack, audit or risk committee minutes, internal audit scope, action tracker, assurance map | A status colour without source evidence should be treated as weak |
This table is deliberately strict. A board should be able to ask for the evidence behind any score and get something more than a narrative answer. The standard is not perfection. It is whether the organisation can show what it knows, what it does not know, and what decision follows.
Framework and regulator mapping
The index will map each dimension to frameworks boards already recognise, rather than inventing a private governance vocabulary.
The backbone is the NIST AI RMF Core, whose Govern, Map, Measure and Manage functions translate cleanly into board evidence: governance owner, system context, measurement and control. We use that structure because it is readable by directors and useful to technical teams. It also aligns with our broader guide to an AI governance framework for UK boards.
For UK regulatory context, the GOV.UK response to the AI regulation white paper confirms a principles-based approach applied through existing regulators. That matters because the index should not imply that readiness means compliance with a single AI statute. It means the board can show how safety, transparency, fairness, accountability and redress are handled in the regimes that already bind the organisation.
Where AI touches personal data, the ICO's AI and data protection guidance is the key source. The index should therefore ask for DPIAs, fairness assessment, governance accountability and safeguards for automated decisions where relevant. In listed-company governance, the FRC's UK Corporate Governance Code page explains that the 2024 Code applies from 1 January 2025, with Provision 29 on material internal controls applying from 1 January 2026. For financial services, the FCA's approach to AI says it does not plan extra AI regulations and will rely on existing frameworks, including outcomes, Consumer Duty and senior-manager accountability.
The practical mapping is this: NIST gives the evidence architecture, UK regulators give the legal and supervisory expectations, and the board turns both into decisions. A benchmark that cannot show that chain is not an index. It is a survey.
Common mistakes before the first report
The first mistake is treating readiness as a single percentage. A one-number score is attractive, but it hides the difference between a board with strong data-protection evidence and weak supplier oversight, and a board with the opposite problem. The first report may include an overall band, but the useful material will sit in the dimension scores and the evidence gaps behind them.
The second mistake is confusing usage with maturity. A financial services firm may have many AI use cases and still lack clean accountability across third-party models. A charity may use fewer tools but have better control of sensitive beneficiary data. The index should measure governance evidence, not enthusiasm.
The third mistake is counting documents without checking whether they operate. An AI policy is not evidence of oversight if nobody knows which systems it covers. A risk register is weak if it updates quarterly while the underlying model, prompt or supplier changes monthly. A DPIA is stale if it was completed before the system's purpose changed. These are the reasons our risk-register work argues for living evidence, not spreadsheet theatre.
The fourth mistake is publishing sector patterns too early. Small samples make organisations identifiable, especially in regulated niches. A first report should suppress thin cells, avoid anecdotal colour unless consented and reviewed, and state its limits in the same document as its findings.
The fifth mistake is using Karl George MBE's review role as a substitute for evidence. Human review matters because it checks whether the method and interpretation are sound. It does not create benchmark findings where the underlying data is not yet sufficient.
Next step
If your board wants a starting point now, use the Board AI Scorecard to test whether the basics are in place: accountability, inventory, risk evidence, data protection, supplier control and board reporting. Treat the result as a working board paper, not as a public comparison.
If the scorecard exposes material gaps, route into the AI governance diagnostic. The diagnostic is the better route where the board needs evidence reviewed, controls prioritised, or a decision on whether an AI system should go live, be paused or be brought under stronger oversight.
The first benchmark report will come later, when the data can support it. That is the point. A readiness index only earns authority if it refuses to publish what it cannot yet prove.
Sources: NIST AI RMF Core · GOV.UK AI regulation response · ICO AI and data protection guidance · FRC UK Corporate Governance Code · FCA approach to AI · Bank/FCA AI in UK financial services 2024